
Chapter 7: Publicizing Your Site (Without Irritating Everyone on the Net)
Revised June 2003
|
|
Chapter 7: Publicizing Your Site (Without Irritating Everyone on the Net)Revised June 2003 |
 This section explains how search services are built, how search engine
sites sell advertising, how a publisher can determine the number of
users who came to a site via a search engine (and what those people were
searching for), how to improve a site's chances of being selected by a
search engine in response to a query string, and how to make sure that
dynamically-served content isn't inadvertently hidden from search engines.
This section explains how search services are built, how search engine
sites sell advertising, how a publisher can determine the number of
users who came to a site via a search engine (and what those people were
searching for), how to improve a site's chances of being selected by a
search engine in response to a query string, and how to make sure that
dynamically-served content isn't inadvertently hidden from search engines.
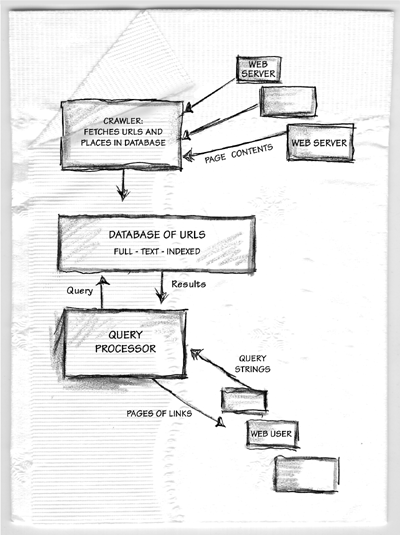
 All the search engines have three components (figure 7.1). Component 1
grabs all the Web pages that it can find. Component 2 builds a huge
full-text index of those grabbed pages. Component 3 waits for user
queries and serves lists of pages that match those queries. Your Web
server deals with Component 1 of the public search engines. When you are
surfing www.google.com you
are talking to Component 3 of that search engine.
All the search engines have three components (figure 7.1). Component 1
grabs all the Web pages that it can find. Component 2 builds a huge
full-text index of those grabbed pages. Component 3 waits for user
queries and serves lists of pages that match those queries. Your Web
server deals with Component 1 of the public search engines. When you are
surfing www.google.com you
are talking to Component 3 of that search engine.
If your site is linked from an indexed site, you do not have to take any action to get indexed because the crawlers will eventual discover it. If you are impatient to get your site indexed or you have recently changed a lot of content or nobody is linking to you, it is worth using the "add my URL" forms on the search engine sites. The specific URLs that you enter will be available to querying users within a few days. Another good way to get indexed is to add yourself to the appropriate pages within the Yahoo and Open directories.
Word
Frequency
all
1
another
1
but
1
each
1
families
1
family
1
happy
1
in
1
is
1
its
1
one
1
own
1
resemble
1
unhappy
2
way
1
You might think that this sentence makes better literature as "All happy families resemble one another, but each unhappy family is unhappy in its own way," but the computer finds it more useful in this form.
After the crude histogram is made, it is typically adjusted for the prevalence of words in standard English. So, for example, the appearance of "resemble" is more interesting to the engine than "happy" because "resemble" occurs less frequently in standard English. Very common words such as "is" are thrown away altogether.
For relatively stupid indexer/query processor pairs, this is where the sorting stops. Smarter engines, however, use some further knowledge about the Web. For example, they know that
 One way to stand tall in most search engines is to buy words. Any time
someone searches with a string containing the word "car" your banner ad
will appear on the page. Search for "Toyota
Sienna" in Google and you'll see a host of "sponsored links".
Google's AdWords system is worth studying. Basically advertisers bid to
appear when users search for particular words. If you want to fight
with Honda and Ford for "new car" it will be expensive per
click-through; for "Erasmus" you can probably outbid the average
philosophy professor pretty easily.
One way to stand tall in most search engines is to buy words. Any time
someone searches with a string containing the word "car" your banner ad
will appear on the page. Search for "Toyota
Sienna" in Google and you'll see a host of "sponsored links".
Google's AdWords system is worth studying. Basically advertisers bid to
appear when users search for particular words. If you want to fight
with Honda and Ford for "new car" it will be expensive per
click-through; for "Erasmus" you can probably outbid the average
philosophy professor pretty easily.
If you can't afford to buy words it is a good idea to focus on collecting relevant documents. Remember that search engines don't index graphics, Flash, or Java applets. What you want is text, text, text. The more text on your site, the more words and therefore the greater chance that you'll have a combination of words for which users are searching. If you want readers to find you in the search engines, it's much better to spend $20,000 licensing the full text of a bunch of out-of-print books than on a graphical makeover of your site.
Relevant and unique information also helps build prominence in search engines by encouraging other Web publishers to link to your site. Google assumes that a page that 100 other people have found worthy of linking to is better than a page that only 2 other pages on the Web point to.
 Does advertising on the Web work? If what you're advertising is another
Web site, the answer seems to be "sort of". Buying words in Google seems
to be the only universally agreed-upon good value.
Does advertising on the Web work? If what you're advertising is another
Web site, the answer seems to be "sort of". Buying words in Google seems
to be the only universally agreed-upon good value.
How much does advertising cost? Web publishers seem to be able to charge between three and twenty-five cents per click-through. Note that a fee is only paid when a user actually cicks on the banner. This is good if you're an advertiser but not so good if you're a publisher selling ads because clickthrough rates are very close to 0, i.e., users are sick of irrelevant advertising and almost never click on ads.
If you have an ecommerce site you may be able to acquire clickthroughs at a much lower cost by operating a referral scheme similar to Amazon's.
If you have a worthwhile not-for-profit site, advertising need not cost anything. Most commercial publishers have unsold banner ad space and they don't like to redesign their pages to serve documents without advertising. Environmental Defense Fund was able to get quite a few banner ad impressions to promote www.scorecard.org. The ads said "Type in your zip code and we'll tell you who is polluting your town" and even had a little zip code entry form that would take users directly to a community page. Publishers are able to set some of their advertising rates as a function of the clickthrough rate on their site overall. They thus welcomed the ads for Scorecard because the clickthrough rate was as high as 3% (versus an industry average of less than 1% at the time, probably 1/100th of 1% now!). If the ads had been ineffective and would therefore have reduced a publisher's site-wide average clickthrough rate, they would have been pulled, however much the publisher might have liked Scorecard.
 Often the user's browser will tell your Web server the URL from which
the user clicked to your site. Any Web server program can log this
referer header (yes, "referer" is misspelled in the
HTTP standard) in the same file where other information about requests
is stored.
Often the user's browser will tell your Web server the URL from which
the user clicked to your site. Any Web server program can log this
referer header (yes, "referer" is misspelled in the
HTTP standard) in the same file where other information about requests
is stored.
Sometimes the referer URL will contain the query string. The very first time we ran a referer report on a server log was on a commercial site. We were all set to e-mail it to "the suits upstairs" when we looked a little more closely at one line of the report. We were giving away "Cosmo Hunk calendars" where each month there was a picture of Fabio or something. A WebCrawler user had grabbed this page and the referer header gave us some real insight into his interests
http://www.webcrawler.com/cgi-bin/WebQuery?searchText=hunks+with+big+dicks&maxHits=25
We decided not to use this particular report to demonstrate our powerful
new logging system to the senior executives of our client, a $3 billion
publisher.
I put the above example in the manuscript of my first book on Web stuff. Read http://philip.greenspun.com/wtr/dead-trees/story to find out how it went over with my publisher at the time.
Sometimes a user talks to the search engine via HTTP POST instead of GET. That makes the referer header much less interesting.
We know that this user is an America Online user because he is coming to photo.net from an AOL proxy server. We know that he is at least mildly naughty because his WebCrawler search has come up with "http://www.photo.net/nudes/" as an interesting URL for him. The user-agent header at the end supposedly tells us that he is using Netscape Navigator (Mozilla) 2.0. If we look a little more carefully, the "compatible" indicates in fact that he is in fact using some other browser that has been programmed to fraudulently advertise itself as Netscape. Publishers back in 1995 wrote scripts to look for the string "Mozilla/2". Those users would be served an "enhanced with frames" site. Presumably the "AOL-IWENG 3.0" browser in use here is frames-compatible and the false advertising as Netscape 2.0 is its way of saying so.www-aa0.proxy.aol.com - - [01/Jan/1997:18:57:21 -0500] "GET /nudes/ HTTP/1.0" 304 0 http://webcrawler.com/cgi-bin/WebQuery "Mozilla/2.0 (Compatible; AOL-IWENG 3.0; Win16)"
Here's an AltaVista user:
This user is more advanced. He's not using AOL. He's making a direct connection from his machine at Truman State University (Missouri). At first glance, it appears that he's had a problem with his car because he is searching for "body painting auto automobile repair". Won't he be surprised that AltaVista sent him to the rather naughty http://www.photo.net/nudes/body-paint? Actually he won't be. Our sharp-eyed friend Jin glanced at it and said "Look at the little minuses in front of auto, automobile, and repair. He was looking for documents that contained body and painting but NOT any of the auto repair words."modem22.truman.edu - - [01/Jan/1997:23:41:08 -0500] "GET /nudes/body-paint HTTP/1.0" 200 7667 http://www.altavista.digital.com/cgi-bin/query?pg=q&what=web&fmt=.&q=body+painting+-auto+-automobile+-repair "Mozilla/3.01 (Win95; I; 16bit)"
Sometimes the Web really does work like it should…
245.st-louis-011.mo.dial-access.att.net - - [01/Jan/1997:20:50:31 -0500] "GET /cr/maps/ HTTP/1.0" 302 361 http://www-att.lycos.com/cgi-bin/pursuit?cat=lycos&query=Costa+Rica%2Bmap&matchmode=or "Mozilla/2.02E (Win95; U)"
This fellow, apparently an ATT Worldnet user, wanted a map of Costa Rica and found it at http://www.photo.net/cr/maps/.
<META name="keywords" content="making money fast greed">
<META name="keywords" content="making money fast greed money
money money money money money money money fast fast fast greed">
A potentially more useful META tag is "description":
<META name="description" content="Journal for sophisticated
Web publishers, specializing in RDBMS-backed sites.">
Normally a search engine will condense the textual content of your site into something resembling a description. Perhaps it will take the first 25 words and serve that up along with the title. This becomes especially problematic if you have a graphics-heavy site with no content at all. If the first few sentences of a page aren't what you'd like people to see when a search engine offers it up as an option, then include a description META tag on that page. Note that currently (June 2003) Google ignores the DESCRIPTION tag.
robots.txt file with the following contents:
User-agent: * Disallow: /samantha
The User-agent line specifies for which robots the
injunctions are intended. Each Disallow asks a robot not to
look in a particular directory. Nothing requires a robot to observe
these injunctions but the standard seems to have been adopted by all the
major indices nonetheless.
Remember that putting something in robots.txt is a very bad way to keep a document confidential. If one wanted to find ibm.com's secret Web content, one might very well start by requesting http://www.ibm.com/robots.txt. If you can be sure that nobody will link to you, you can keep a Web directory reasonably private merely by refraining from creating any internal links. Of course, if it is truly confidential information then you will probably want to password-restrict the directory.
More: http://www.google.com/webmasters/faq.html has some useful tips for META tags that will cause pages to be excluded from Google's cache.
Sites that are all generated by scripts at request time may scare off some search engines. Instead of having URLs that look like "http://yoursite.org/one-article.asp?page_id=37" it may be safer to program the site so that the same content is available at "http://yoursite.org/articles/37/".
 Here's what you should have learned in this chapter:
Here's what you should have learned in this chapter: